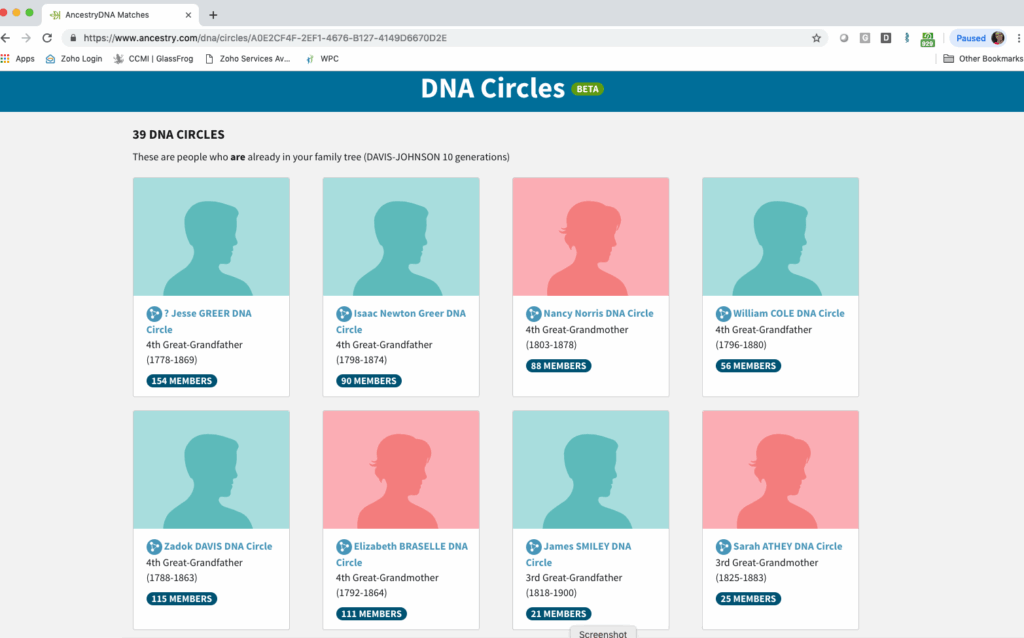
Back in the early days of DNA at Ancestry, there were DNA Circles. According to the Circles White Paper, (no longer available on their website), “a DNA Circle™ … is created by combining pedigree and IBD information from across theAncestryDNA member database.”
Screenshot of DNA Circles in 2019, before they disappeared.
Next came ThruLines® which also combined pedigree information with match data.
Anonymized ThruLines® Dashboard
The caution with both approaches is the combination of DNA information, derived from a technical process, with pedigree information, derived from fallible human processes.
The addition of Enhanced Shared Matching in 2024 gave Ancestry users with the ProTools subscription the ability to do much more powerful analysis of their matches. (Notably, this feature had been available at every other testing site prior to 2024.) The shared cM amount between shared matches increases the number of matches that can be placed into speculative trees which can be validated at BanyanDNA. Since Ancestry has the largest database of DNA testers, this opened many doors for genetic genealogy.
Autoclustering has been available at MyHeritage for many years. A clustering tool is available at GEDmatch and other third party services have offered clustering for years. Now Ancestry has given ProTools subscribers Matches by Cluster. Clustering relies on genetics alone, grouping matches who share DNA with each other. The genealogist then uses that information to determine which ancestor the cluster may be associated with. This is the best use of DNA – using it to point to where to look for documents to explain the relationships between the matches.
Cluster diagram from Ancestry. A list of the clusters and the matches appears below this diagram.
Tips for working with clusters:
Understand who is included in the clusters and why. Read the FAQs on the Ancestry Matches by Cluster page.
Take a good luck at the cluster and know what you are seeing. Your matches appear in a list in the same order along the side and across the top. You are the light tan background. Coloured squares indicate where your matches match each other. The dark multi-colored diagonal line indicates where your matches match themself, giving you a useful point of reference. Darker grey squares that are outside of a cluster indicate where your match matches someone not in the main cluster. An algorithm decides who goes in what cluster. This darker grey “confetti” can indicate useful information about how the clusters might be associated with each other, for example, a generation further back, a more recent generation, or multiple relationships. Note: clustering is not as useful for people who have endogamy in their family. There are ways to adjust clusters, and Ancestry says this ability is coming soon.
Identify Most Recent Common Ancestors for each cluster. Look at the trees and search for surnames, and/or locations, and/or times in common. I often take a screenshot of the clusters and then annotate them as I determine the MRCA.
Build a tree based on what you’ve learned and validate it on BanyanDNA or by analyzing shared DNA amounts and relationships individually.
Write down what you’ve discovered and then use it to do documentary research. Revise your summary after your documentary research.
Set up a routine to repeat the cluster analysis as the database grows.
Have fun with the Ancestry Matches by Cluster tool!
The DNA world received the news last week that 23andMe filed for bankruptcy. This has been a long time coming. I’ve collected some of the best information about the situation here:
To get the information straight from 23andMe, read their press release here or their open letter to customers.
The Vancouver Sun provided a Canadian perspective here, stating that experts advised deleting data. NPR provided analysis as well. The Attorney General of California posted a consumer alert.
You are the only person who knows your own tolerance of risk. I have not used 23andMe as much as I use other DNA testing company websites, since the company was not designed to assist people with genealogy research. Yes, I did look for matches there and use the chromosome browser (when it existed), but the emphasis at 23andMe has always been on the health aspects of DNA.
My hope is that those leaving 23andMe will download their data first (it’s what they paid for) and transfer their DNA to MyHeritage, FamilyTreeDNA, or LivingDNA. These three companies accept autosomal DNA transfers. All three have unique tools and customers and spotless records for privacy and security. Maybe I’ll see you there!
Several times a year I am asked about a small segment match. For the purposes of this blog, I am considering anything below 8 centimorgans (cM) a small segment.
Many experienced and eloquent genetic genealogists have written on this topic. The titles of their articles include a spoiler alert:
To understand why small segments are deceptive, it’s important to understand how DNA matching is measured. When you look at a DNA match list at any company, you will see the shared cM amount between you and your match. But that’s not all they use to determine if you are a match. Each company has a threshold for sharing which incorporates shared cMs and other characteristics of the DNA data. This may include matching on one or both chromosomes (remember you get one from each parent), the SNP density (referring to how rich the genetic information is – a very complex topic I don’t pretend to understand), the number of segments you share, and endogamy. Endogamy is the situation where groups of people, often geographically or culturally isolated, partnered with each other over hundreds or thousands of years. The result is that you can have many relationships with your matches, which inflates the amount of shared DNA. If you come from an endogamous population, you need to share more DNA in larger segments to be considered a DNA match. The ISOGG wiki has a table that compares the DNA testing companies matching criteria in detail. Search for “Criteria for matching segments” in the ISOGG Wiki link.
In genetic genealogy, we create images of shared cMs that make measuring DNA look like a simple thing you could do with a ruler, with coloured bars indicating shared segments of DNA. In the image below, I’ve used DNA Painter, importing data from known paternal DNA matches in the blue shaded portion near the top of the image and known maternal matches in the pink section in the lower part of the image. Each different coloured bar represents a different shared ancestor.
A public version of my chromosome painting from DNA Painter
The most basic definition of shared cM dances around the issue of what is actually being measured:
cM: “a unit of measure for autosomal DNA segments. The more DNA we share with someone in centimorgans, the more closely related we are.” Leah Larkin PhD
These simple images and definitions cover up the wealth of science behind what is actually being measured. The ISOGG Wiki provides the following definition for centimorgan:
A centimorgan…is a unit of recombinant frequency which is used to measure genetic distance. It is often used to imply distance along a chromosome, and takes into account how often recombination occurs in a region. A region with few cMs undergoes relatively less recombination. The number of base pairs to which it corresponds varies widely across the genome (different regions of a chromosome have different propensities towards crossover). One centiMorgan corresponds to about 1 million base pairs in humans on average. The centiMorgan is equal to a 1% chance that a marker at one genetic locus on a chromosome will be separated from a marker at a second locus due to crossing over in a single generation.
Whoa! This definition reminds me that I will never understand everything there is about genetic genealogy, and that there are scientists who developed the strategies the DNA testing companies use. Blaine Bettinger has summarized company information on segments and matching here. I have to keep reminding myself that cM measurement isn’t like the length of ribbon, it’s about how likely it is that the DNA will split apart when an egg or sperm is being made.
False matching
Even with all of this science, a match on your match list at a DNA testing company might not be real. How can that be?
That small segment might be a pseudosegment, a false segment which leads to false matches. This can happen because the DNA company takes your DNA apart into the two chromosomes and puts it back together again. Sometimes it is put back together wrong, weaving back and forth between the father’s and mother’s DNA. The smaller the segment, the greater the chance it is a pseudosegment. (For more information and an illustration, see Identical By Descent in the ISOGG Wiki.)
If you have transferred your DNA to another testing company (FamilyTreeDNA and MyHeritage allow DNA transfers) or you are using the third-party site, GEDmatch, your small segment might be due to imputation or be from a known pile-up region.
Imputation. Whenever anyone does a DNA test, there are some regions that can’t be read (“no-calls”) and those sections are estimated (imputed). This happens at every DNA testing company. If a DNA company has changed their testing chip over the years they use imputation to allow them to analyze the DNA in the sections of the chip that differ. For companies that accept transfers and GEDmatch, there will always be imputation because of the number of different chips they are analyzing and comparing to each other. Every company does imputation using the methods their scientists have developed. Imputation can create a small segment and it can also separate a larger segment into two segments. Roberta Estes has a three part series in her blog on imputation starting here.
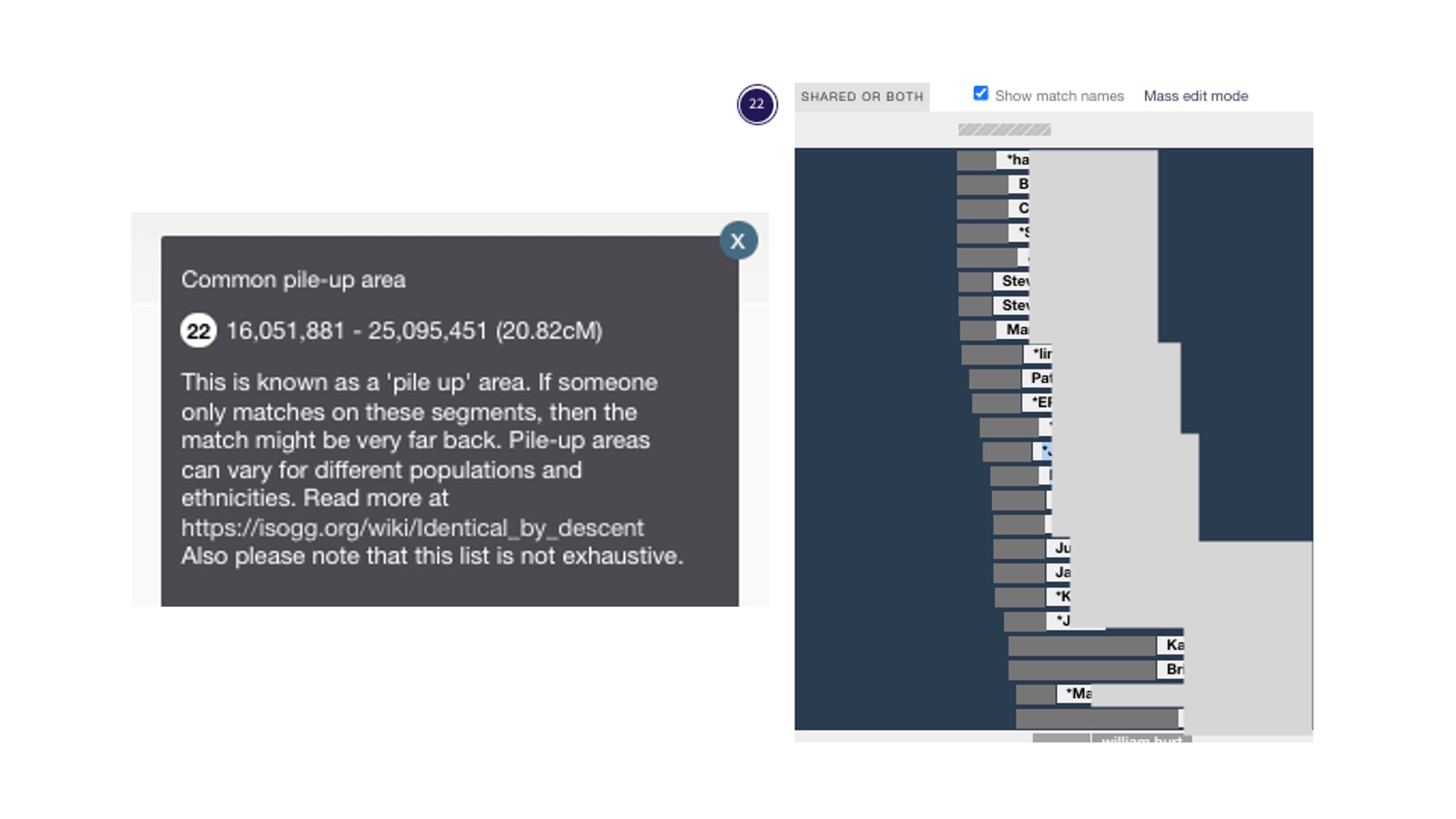
There are pile-up regions where many people have the same DNA. These are also called excess IBD (Identical by Descent). Testing companies don’t report those regions (they have algorithms that leave them out of DNA matching), but GEDmatch reports these regions. More on that in the ISOGG Wiki. Jonny Perl has included the known pile-up areas in DNA Painter; a grey bar with horizontal stripes appears above each chromosome where they are known to happen. In the image above of chromosome 1, you can see the grey bar in the middle above the blue-shaded area. When you click on the grey bar, you will find additional information about that pile-up region. I’ve provided a close-up below of a pile-up region for Chromosome 22. The explanatory text box is on the left. The painting on the right shows data from GEDmatch. In 2023, I shared DNA in this pile-up region with 75 people. I know it’s a pile-up area because there are so many matches and I can see the grey bar with the diagonal stripes at the top. I don’t consider these DNA matches even though they share 10-14 cM with me on that chromosome.
DNA Painter notation about a pile-up area on Chromosome 22 and an example of my match data from GEDmatch
Two additional complications with small segments
Many people do DNA testing to learn more about their country or region origin. Some companies call this ethnicity results. The best term for this kind of data is biogeographical ancestry – where your distant ancestors were at a point in time. That information is also in our chromosomes. That’s complication number one. Your small segment could be Identical by Population, as described by Roberta Estes. Everyone or almost everyone who descends from people on the same migratory population path for thousands of years has the same segment of DNA.
Complication number two pertains to your goal. Many of us do DNA testing because we want to find our ancestors and give them names. We can do that if our matches occur within a genealogical time frame, defined as the time when their might be documents to help us. Your small segment could be from an ancestor not within a genealogical time frame. Using simulated DNA data, Leah Larkin has found a 10 cm match could be a 9th cousin, meaning you share 8x great-grandparents. For most of us, this is at the edge of documentary genealogy. A smaller segment, such as 7 cM could be from a 10th great-grandparent or a 40th great-grandparent or there is a 58% chance it is false. (Simulated data from Leah Larkin. Data on false segment size is from Tim Jantzen in the ISOGG Wiki. See Blaine Bettinger for company specific information on false segment sizes. )
At the third party DNA site, GEDmatch, you can alter the matching thresholds to below what the testing companies are doing. This is where the danger lies. Just because you can set a lower threshold doesn’t mean you should.
But I match someone with a LOT of small segments!
If all of the segments are small, the most likely explanation is endogamy. As mentioned earlier, the strategy for working with endogamous communities is to use larger segments and avoid the small ones. If you are working with an endogamous community, you will be applying different strategies to analyze your DNA. Paul Woodbury has a two part series Dealing with Endogamy. He also lectures and teaches courses. You can seek out presentations and courses by Dr. Adina Newman. Diahan Southard offers an Endogamy Course (full disclosure, I work for Diahan Southard as a coach). Leah Larkin, the DNA Geek, periodically offers an Endogamy lecture and writes about Endogamy in her blog. I recommend all of these from personal experience.
A rational approach to using segment data
With documentary genealogy, we know we need to start with the present and work our way back. You can do the same thing in genetic genealogy using segment data. Jim Bartlett, author of the blog segment-ology, calls this “walking the segment back.”
Let me introduce you to some of my ancestors and DNA-tested cousins in the image below. Skip to the next paragraph if this type of family tree diagram is familiar to you. If it’s not, what follows is a description of the diagram and a reminder of relationship terminology and abbreviations. In the image, I’m at the bottom in a light blue box. My dad is immediately above me, then my granddad, then my great-grandparents, Walter Hale Davis and May (Hilton) Davis in green. All the cousins that I share with the ancestral couple of Walter and May are in green. SG, CP, MR, and I are second cousins, because second cousins share great-grandparents. PK, CP’s parent, my dad, MR’s parent, and JS are all first cousins to each other because they share Walter and Mary as grandparents. Since I am one generation younger than these first cousins, I am their first cousin once removed (1C1R). Moving up the diagram, Walter’s parents were William Hale Davis and Sarah Jane (Ellis) Davis. A descendant of Walter’s sibling has also done a DNA test. RD is shown in a light green to match William and Sarah Jane. Since William and Sarah Jane are RD’s great-grandparents and RD is one generation older than me, we are second cousins once removed (2C1R). And up at the top are my 3x-great grandparents, Rev. T.O. Ellis, MD and his wife, Elizabeth (Long) Ellis, in the dark green. I share this ancestral couple (T.O. and Elizabeth) with two cousins (siblings, GS and DM) also in dark green in the lower right. T.O. and Elizabeth are the 2x-great grandparents of GS and DM, so we are third cousins once removed (3C1R).
Ancestors and corresponding DNA matches in relationship to me
MyHeritage and FamilyTreeDNA allow DNA testers to download the segments you share with your DNA matches. If you know your relationship to a DNA match, you can assign the segment to an ancestral couple. In the image below of Chromosome 1, I started by “painting” the DNA from my great-grandparents, Walter Hale Davis and May (Hilton) Davis with green. You always receive DNA from great-grandparents, so that’s a great place to start painting your DNA. I painted the segment data from two 1C1R (PK and JS) and three 2C (SG, CP and MR). I didn’t really need SG since their parent has also tested, but it is a good illustration of how DNA segments tend to get smaller every generation. The lightest green match (RD) is a 2C1R who shares my 2x great-grandparents, William Hale Davis and Sarah Jane (Ellis) Davis. If you look at the comparison of PK to RD, you can see that RD is contained within the green segment from my great-grandparents. This makes sense. The DNA from PK came from either my Davis ancestor or my Hilton ancestor, and it’s clear that most or all of it came from Davis, since I don’t share Hilton ancestors with RD. Then I have two siblings, DM (13.2 cM) and GS (11.8 cM) who both descend from my 3x-great grandparents, Rev. Thomas Oliver Ellis, MD and Elizabeth (Long) Ellis. The same pattern holds: the segment fits within the segment from RD, who is both a Davis and an Ellis. Dark green is either Ellis or Long or both.
Detail of Chromosome 1 DNA Public Version of a DNA Painting at DNA Painter.com
I may some day find a cousin who descends from Rev. Ellis’ father, Josiah Shelton Ellis, or more distant ancestors, but the chances get increasingly remote as we go further back in time. If an ancestor has no or few siblings, the line could have died out. If there are recent immigrants, they may not be in the testing databases. By using this methodology, I can be more confident that a smaller segment came from a more distant ancestor. Note: The smallest segments I painted are both over 10 cM and came from 3x great-grandparents and 3C1R matches. The average segment size for a 3C1R is 16 cM based on simulated data from Leah Larkin.
If you are interested in using segment data, consider encouraging your matches to upload to MyHeritage. Why? It’s free to upload your DNA, they have good privacy protections, and in addition to being able to gather the data for chromosome painting, there are other useful tools for genealogy at MyHeritage.
The constant plea: Test the oldest generations of your family now!
We can enhance our reach by testing the oldest generation. They will have larger segments to work with and are one step closer to your ancestors. If you have any older relatives (parents, aunts, uncles, cousins one generation older), buy a DNA test for them. (Watch for sales!) Then visit them personally and make sure they do all the steps for the DNA kit to be activated and usable.
Summary
Genetic genealogists avoid using small segments when making genealogical conclusions. There is science behind the limitations of DNA matching. Genetic genealogy needs to be treated like documentary research: start with the present and work your way back.
Every year brings new tools, websites, and approaches for genealogists to try. 2024 was exceptional! Here are four innovations that transformed my work, ranked by their impact:
1. BanyanDNA
Leah Larkin (the DNA Geek) and Margaret Press (of the DNA Doe Project) teamed up with developers and statisticians to create BanyanDNA, a tool many of us didn’t know we needed. This web-based app lets you draw complex family trees and check if the shared cM amounts match your diagram. And you don’t have to limit yourself to one DNA tester. Any pairwise comparison of DNA between any two people on the tree can be included.
BanyanDNA has become essential for me. I can run 1,000–10,000 calculations to simulate recombination randomness, validating my tree or finding the best placement for a mystery person. It even handles intricate relationships, like cousin marriages or double connections.
For example, I mapped a cousin marriage between the children of two of my 3x-great-grandparent couples: Holloway Key and his wife Catherine, and Thomas Adam Walker and his wife Julina Allen who lived in Benton County, Tennessee. In the image above I used red lines to show the descendants of the Key couple and blue lines to show the descendants of the Walker-Allen couple. The pink and purple lines represent where the two Key brothers married two Walker sisters. My mother, Gladys, and two of her siblings are DNA testers and I’ve shown three of their matches who are related to them through both couples. This kind of situation can throw off the expected amount of shared DNA, but BanyanDNA can handle it. Below is a validation run that shows me that there is one match that falls outside the expected range of shared DNA. Often when I see that result, it means I have drawn the tree wrong or mistyped the amount of shared DNA.
Summary:
I use BanyanDNA to:
Diagram complex trees
Record shared DNA between large numbers of DNA testers
Validate my work using statistical simulations
Place unknown matches on the tree.
What you need:
A good understanding of relationships and family trees
Shared DNA amounts (see Enhanced Shared Matching below)
A willingness to learn how to use BanyanDNA. There are recorded tutorials here, a BanyanDNA User Facebook group, and office hours for free (publicized on the Facebook group). Leah Larkin offers a webinar tutorial for a small fee.
Basic statistical skills to interpret the calculations.
Patience! Large trees with many matches take time!
2. Enhanced Shared Matching at Ancestry
MyHeritage has long offered excellent tools for genetic genealogists, like downloadable DNA segments and AutoClusters. This year, Ancestry followed MyHeritage’s lead and introduced Enhanced Shared Matching, which shows the shared DNA between you, your matches, and their mutual connections.
The image above is a privatized look at Enhanced Shared Matching at Ancestry. My DNA match is CP and I know how I am related to her. With Enhanced Shared Matching (available with an additional subscription), I can see not only how much DNA I share with our shared matches, I can now see how much DNA CP shares with them. I sorted this list by how much they share with CP which helps me discover more about her family. For example, the first match, a, shares 603 cMs with CP but only 51 cMs with me. 603 is in the range of a first cousin to CP. Match a has a 9 person tree with only two visible people on the tree whose names are not found in my family tree. But knowing they are possibly a first cousin to CP means I can likely figure out their exact relationship to me.
All of the Enhanced Shared Matching data can be entered into BanyanDNA so I can validate this branch of my family tree.
Summary:
I use Enhanced Shared Matching to:
Understand how my matches are related to each other.
Place matches without full trees on my tree.
Supply data for BanyanDNA calculations.
What you need:
A ProTools subscription (currently $10 USD/month)
Knowledge of shared DNA amounts
Tree-building skills
Ability to research DNA matches with incomplete or no trees.
3. Full text search at FamilySearch
FamilySearch, the world’s largest free genealogy resource expanded its capabilities in 2024. Its new Full Text search of historical records (available at FamilySearch Labs) uses AI-driven optical and handwriting recognition to unlock thousands of previously unindexed records, such as land deeds and probate files. For those working on reparative genealogy, the Freedmen’s Bureau Records are part of the collection that can be accessed.
From the FamilySearch Labs home page, click on “Go To Experiment” under the Full Text option. This will take you to a search page.
Use the keyword search to enter your names – that provides you with more opportunity to find your ancestors. I entered Calvin Whitney in Keywords, and Maine from 1800-1870 in the year range to discover the record below:
Calvin Whitney is my 4x great-grandfather. I don’t know a lot about him other than he died in October of 1832 in Thomaston, Lincoln County, Maine. His son, William E. Whitney, left Thomaston in October of 1849 for the California gold rush and later built four lime kilns at the foot of Mt. Diablo in Contra Costa County, California. This deed describes the property that Calvin Whitney purchased from David Watson in November of 1827 and that Whitney had “the liberty of digging & carrying away the lime rock from said land.”
Summary:
I use the FamilySearch Labs Full Text Search to:
Find digitized records that are not indexed
What you need:
A search strategy using keywords, places, and date ranges.
Patience-more records are added regularly
This brings us to the final aspect of my genealogy work that changed in 2024: my use of AI.
4. Artificial Intelligence (AI) and genealogy
AI is revolutionizing genealogy. In late 2023, I joined Steve Little when he first offered the “AI for Genealogists” course through the National Genealogy Society. In the course I learned how to do the basics with AI: summarize, extract, generate, and translate. Much of my use of AI was confined to making fun images in my brand colour scheme for presentations.
Image created by DALL-E and me.
The potential for AI became clear during a reparative genealogy project. I was provided with a Civil War diary of the ancestor of my client. This project documents the people enslaved by the client’s family on Gwynn’s Island, Virginia. I used ChatGPT to transcribe the diary and to create lists of the people and places mentioned in the diary. AI saved me hours, though I still had to check its work. I asked ChatGPT to write a commentary on the contents of the diary based on historical context. It was fascinating! Here’s the conclusion:
Conclusion
The diary of Mary T. Hunley is a compelling window into the experiences of Confederate civilians during the Civil War. While shaped by the author’s biases and Confederate loyalty, it highlights the war’s disruptive nature, the agency of enslaved people, and the fragility of Southern society. It stands as both a testament to personal endurance and a reflection of the deeply ingrained injustices of the antebellum South.
I have a long way to go before I do some of the amazing things genealogists are doing with AI. There’s a great Facebook Group, Genealogy and Artificial Intelligence (AI), Steve Little blogs and speaks regularly, and there’s a podcast, The Family History AI Show, to help you keep current. Nicole Dyer and Diana Elder at Family Locket also teach, blog, and podcast about using AI in their genealogy work.
Summary
I use AI tools to:
Transcribe handwritten documents
Summarize lengthy articles or records.
Create tables and lists from documents.
Create images.
Understand historical context.
Edit and refine my writing (including for this blog entry!)
What you need:
Awareness of privacy and copyright concerns.
Knowledge of Large Language Models (LLMs).
Practice, practice, practice.
Careful review of AI outputs
Final Thoughts
Genealogy is ever-evolving, and 2024 raised the bar with transformative tools like BanyanDNA, Enhanced Shared Matching, Full Text Search, and AI. Each one has enriched my research and streamlined my workflows. What’s next for genealogists? I can’t wait to find out!
I’ve always been a fan of what used to be called “Citizen Science” and has recently been re-named “Community Science.” I contribute birding data to ebird. I was a volunteer atlasser for the BC Breeding Bird Survey in its early days and I continue to support my husband on the annual survey. We start at the crack of dawn and he counts birds while I drive and keep the tally.
I’m excited to have the opportunity to support genetic genealogy. Blaine Bettinger, the genetic genealogist who is behind the Shared cM Project on DNA Painter, has opened submissions for the next update. The goal is over 100,000 submissions. He hopes to release the update in early 2023. Now’s the time to contribute! There are two ways to do it.
Through this spreadsheet link which is a great option of you have a lot of data.
If you are unfamiliar with the Shared cM Project, it is the go-to place to check genetics vs. genealogy. That’s the step in the analysis when you see if you and your DNA match share the amount of cM that will help you confirm or figure out a relationship. You can get these predictions from each of the testing companies. That’s the notation by your match that says “2nd-3rd Cousin.” Each company uses their own data and information, which could be based on faulty trees. What’s different about the Shared cM data is that it is crowd-sourced. Genealogists who have confirmed the relationships through documentary research provide the data. That’s us! This will be my third time contributing data.