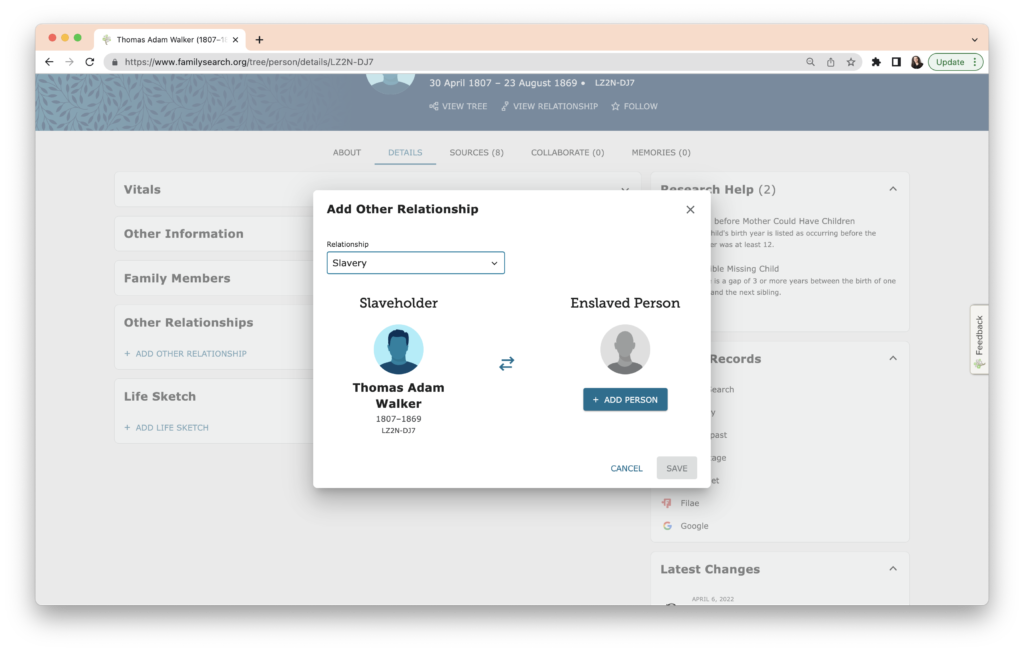
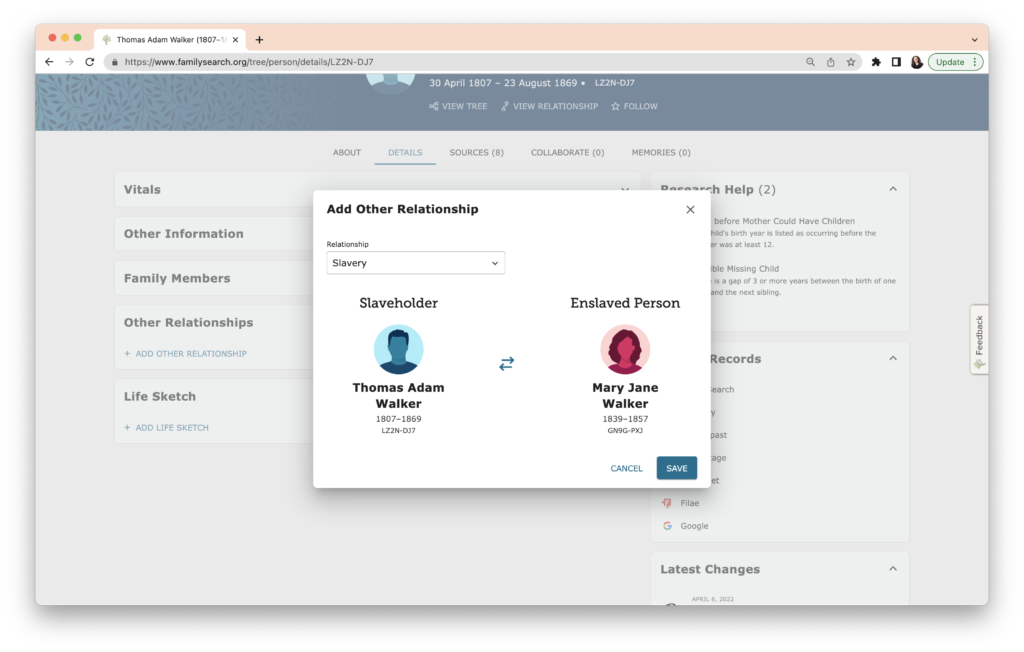
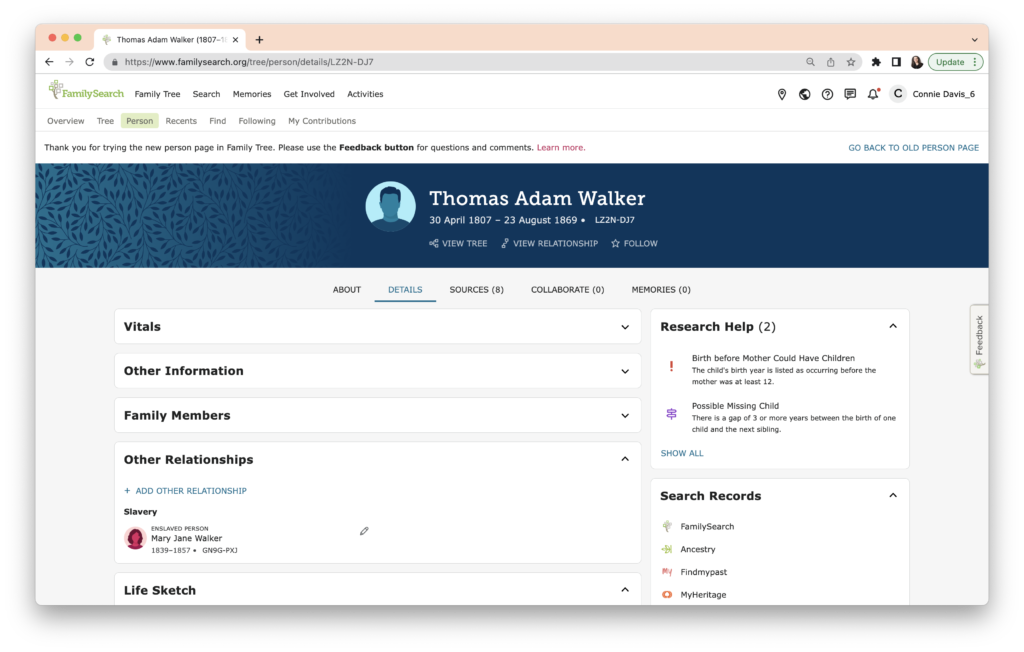
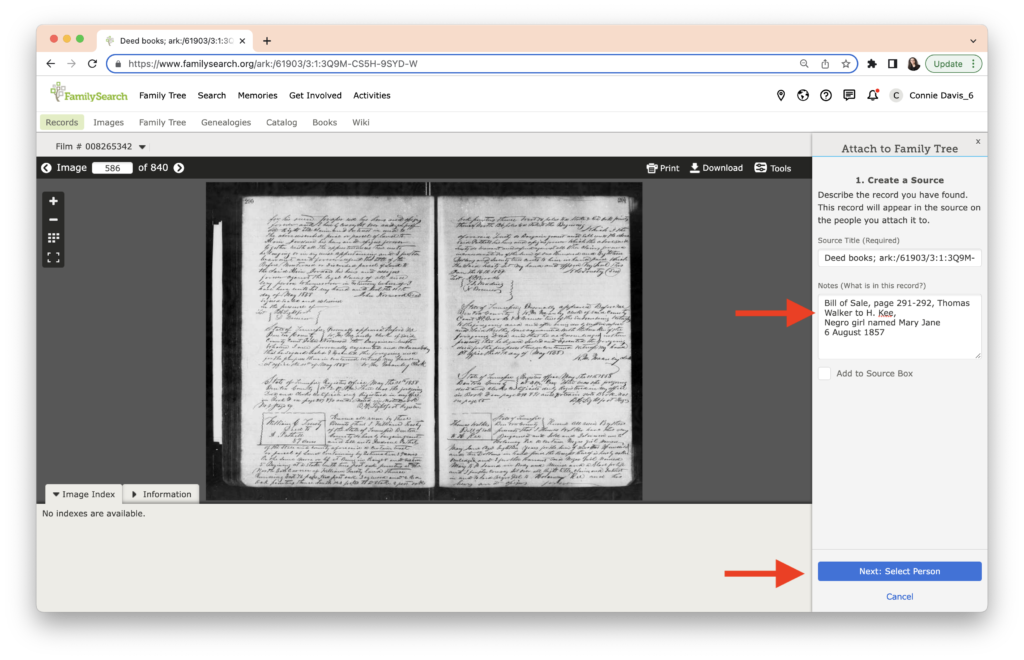
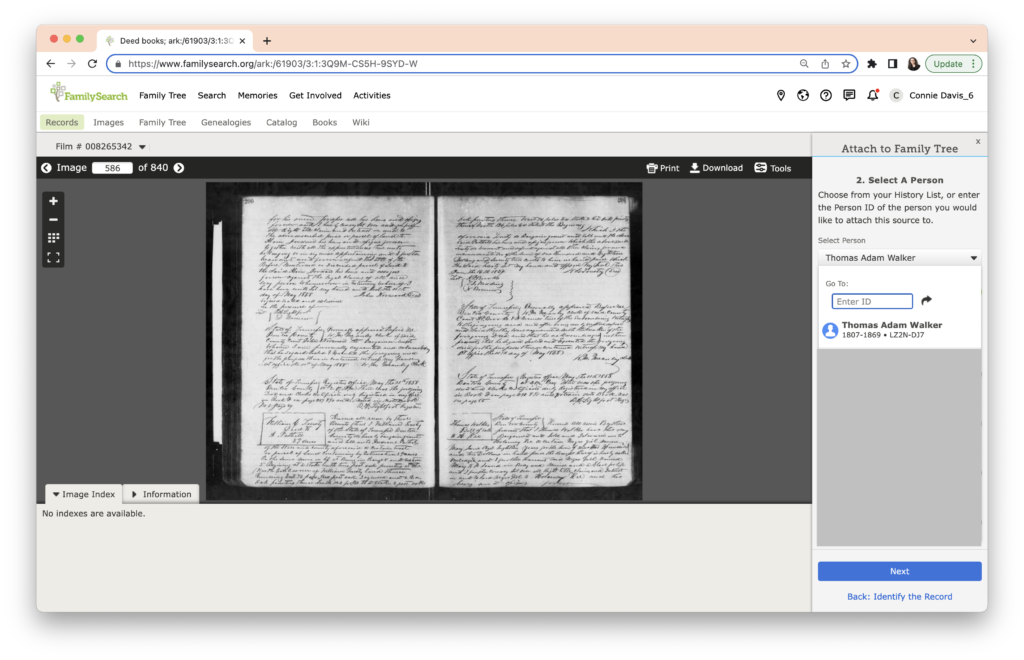
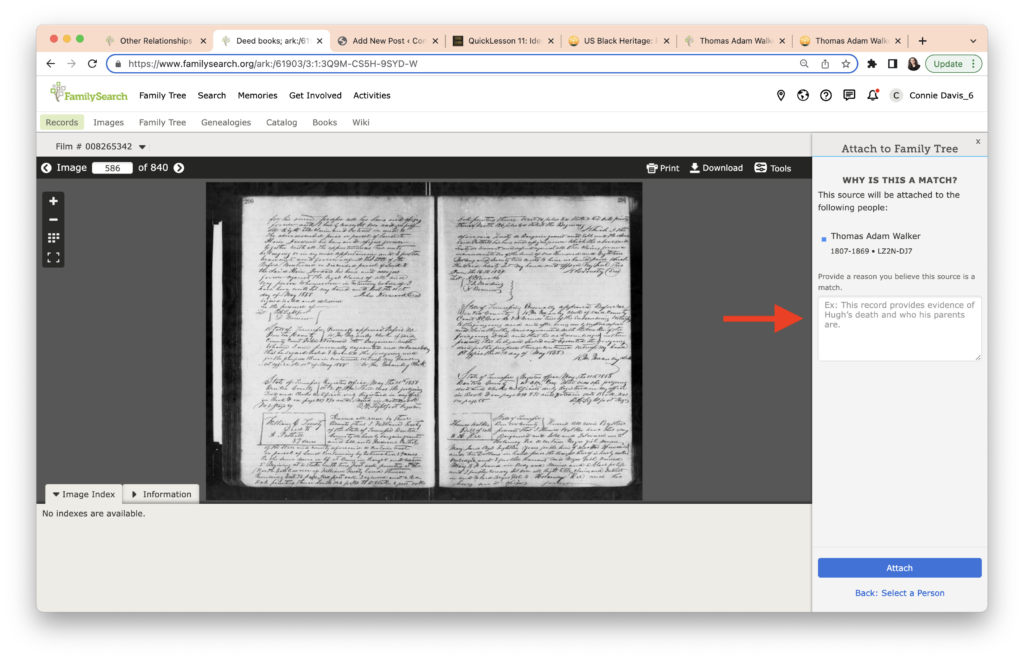
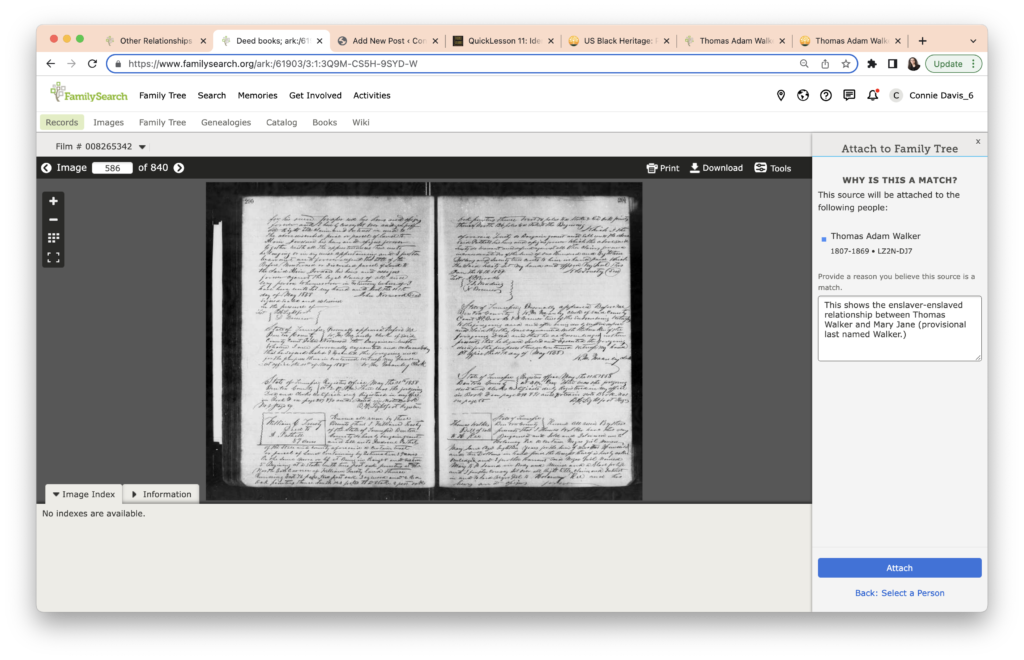
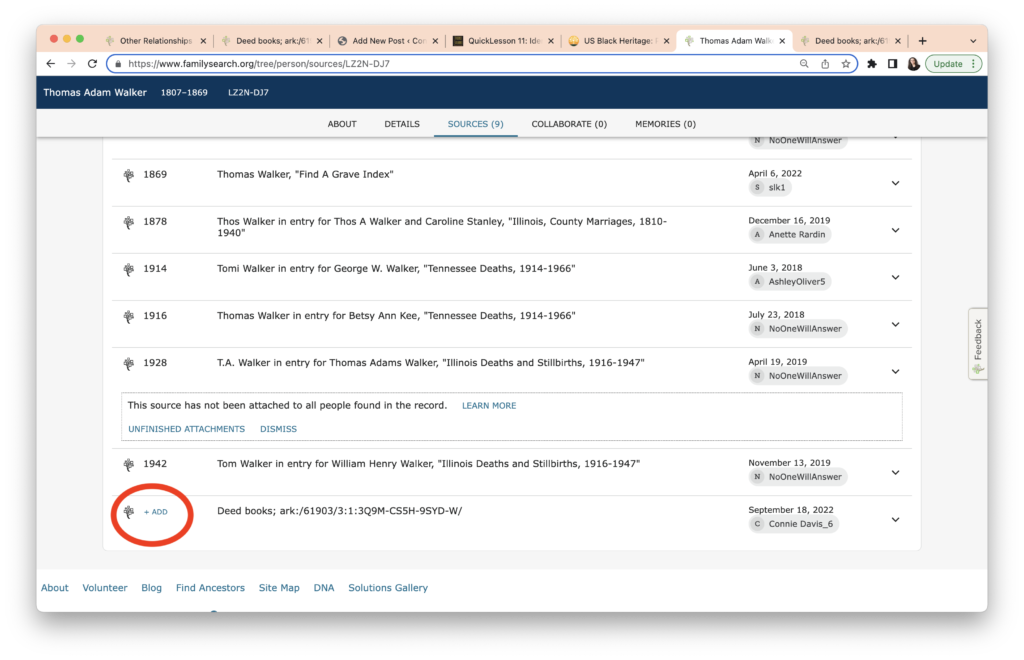
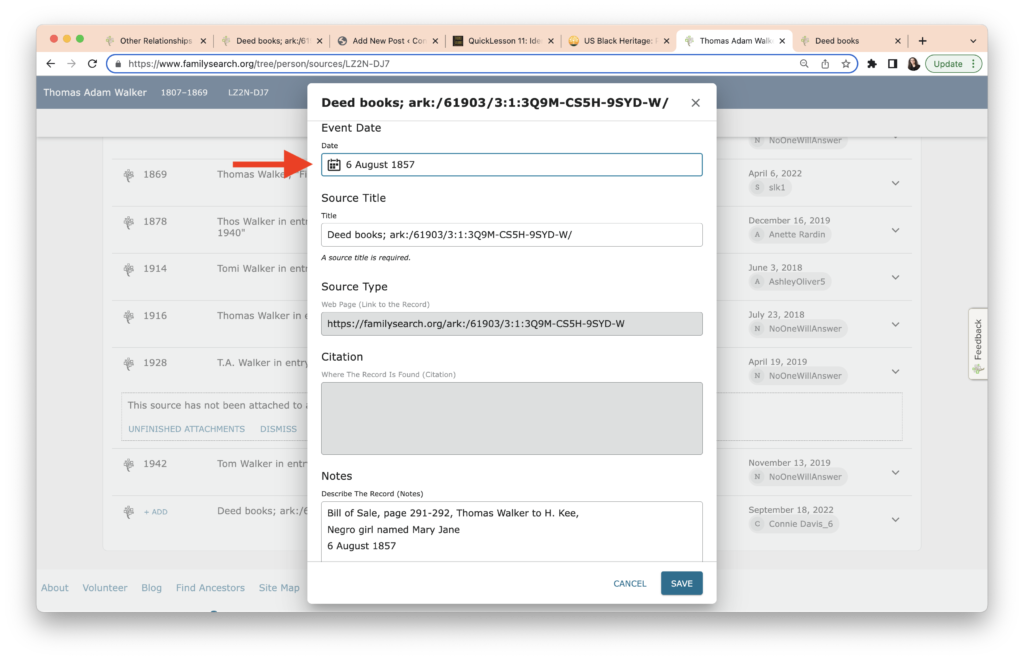
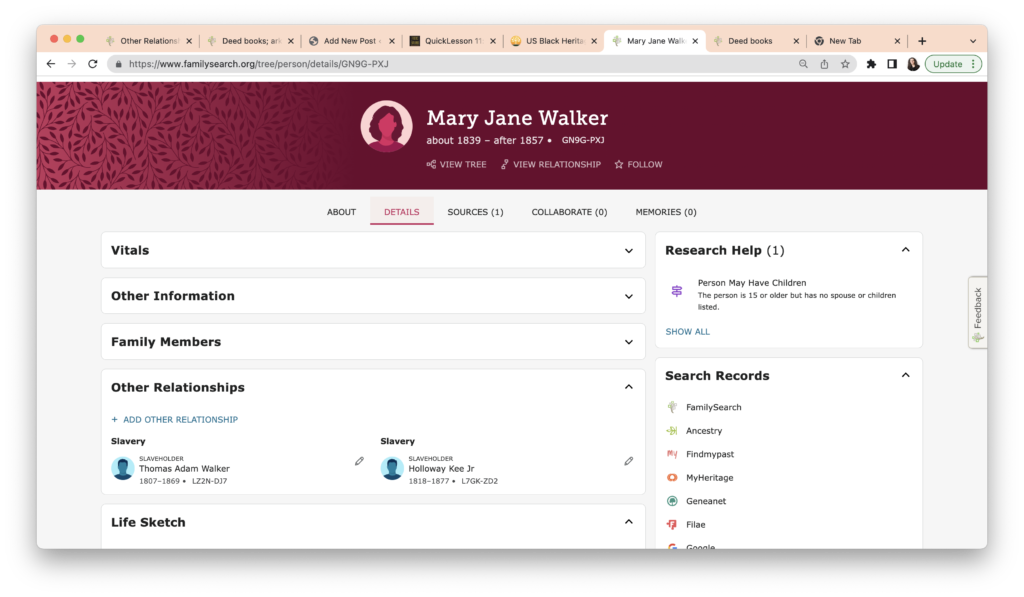
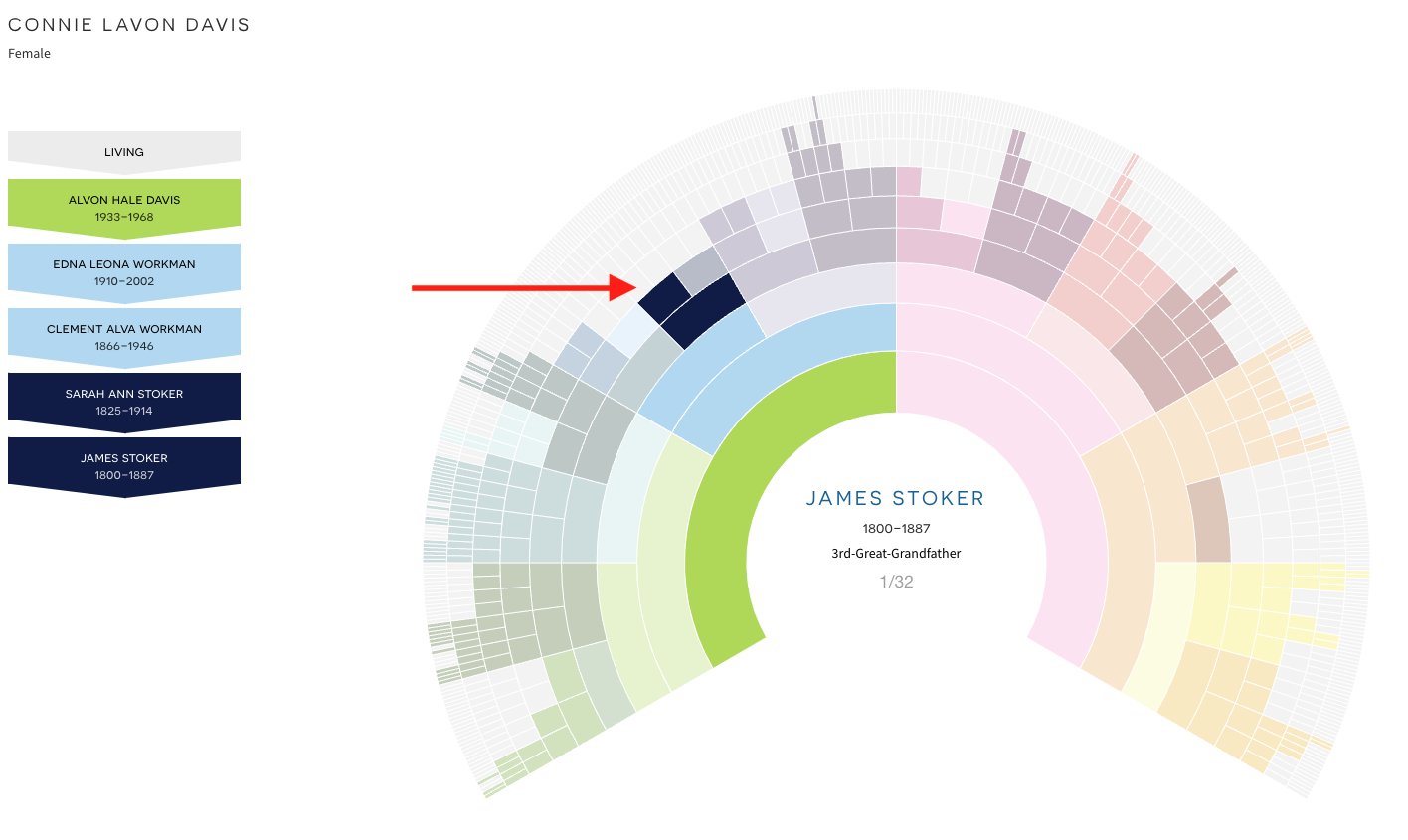
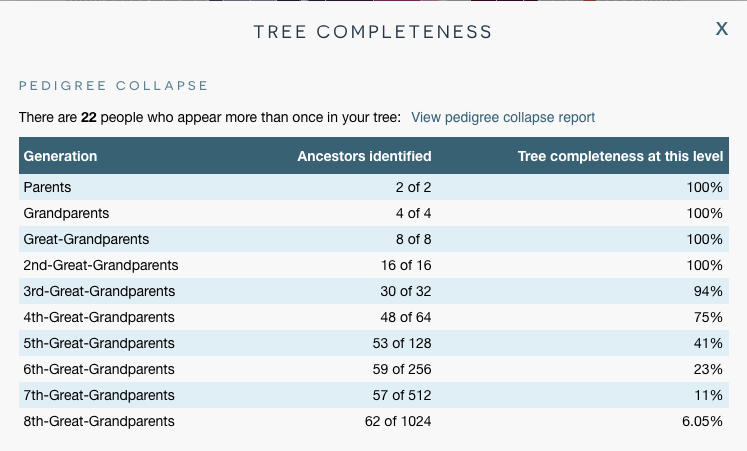
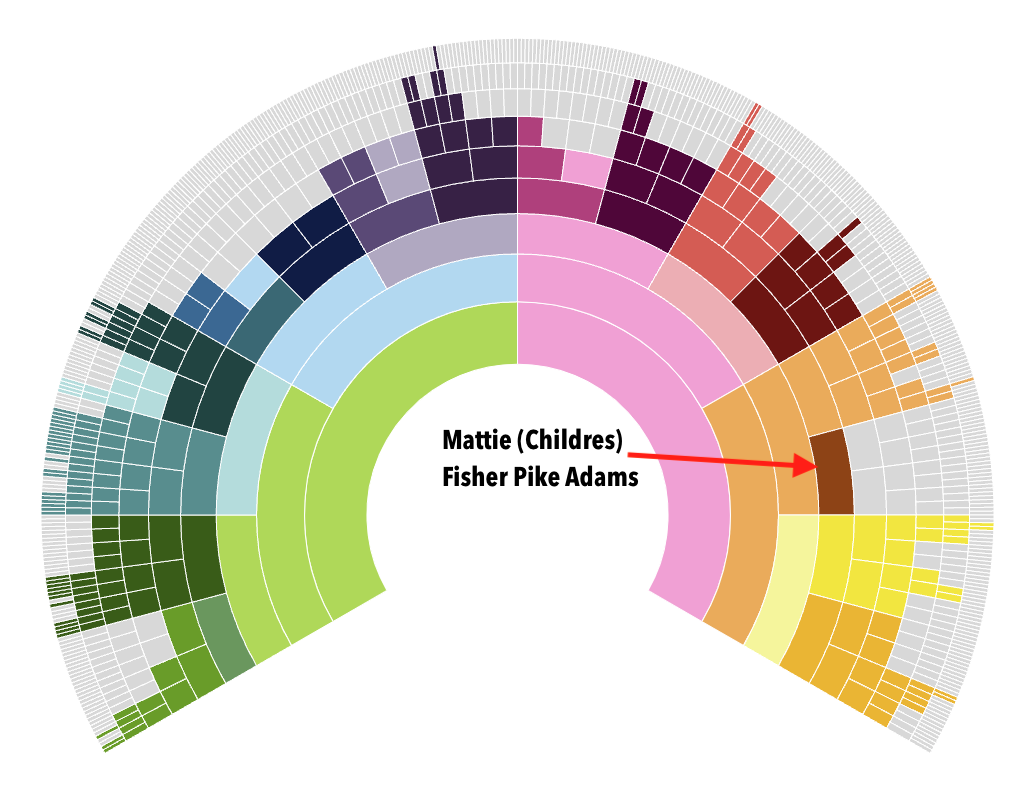
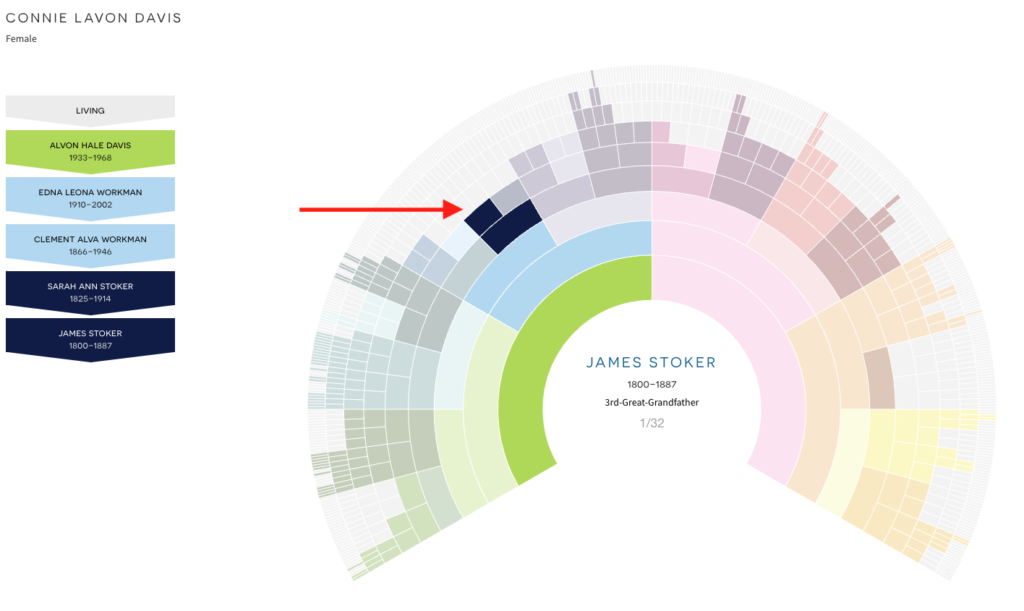
The task this week was to analyze our existing evidence from our timeline. Elizabeth Shown Mills revolutionized genealogy when she described The Evidence Analysis Process Map. Another great way to consider the genealogy research process was developed by Marc McDermott based on Elizabeth Shown Mills’ process map.
I looked at each entry in my timeline and considered what question I was trying to answer with the information in that entry. Then I analyzed the type of source, the type of information and the type of evidence.
Sources: containers of information
- Original source describes a document or artifact (like a cemetery marker) created at the time of the event. A duplicate original was created by the same person at the same time as the original like a clerk rewriting a deed in a minute book, or the enumerator making a duplicate copy of the census. For some duplicate records, more detail can be found in the originals, such as loose papers for an estate. Image copies are photographic reproductions and are considered originals when you don’t detect any alterations and can see the entire image.
- Derivative sources include indexes, transcripts, or abstracts created from an original. Mistakes and misreadings may conflict with the original. Find the original whenever possible.
- Authored sources are written works that combine information. Examples include online family trees, biographical sketches, family histories, and research reports. There may be original sections in an authored source. Authored sources can point towards original sources.
Information: Details within the source
Within an individual source, many pieces of information can sometimes be found.
- Primary: firsthand knowledge. The person who provided the information was present at event. For example, a mother who provides her children’s dates of birth, a spouse providing information about their marriage date and place.
- Secondary: secondhand knowledge. The person who provided the information was told the information by another. The classic example is a child providing the birth date of their parent for a death certificate.
- Undetermined: informant unknown. The person who provided the information cannot be determined.
Different types of information (facts) can be in the same source. The classic example of a source with mixed information is a death certificate with a child as the informant, and a doctor recording some information, and a clerk other parts. The child was not present at their parent’s birth, so the information about date and place of birth of the deceased is secondary. The death day, place, and cause were recorded by the doctor, who is considered to have been present. (As a nurse, I know it was likely the nurse who was present and gave the information to the doctor!) If the informant is blank, then the birth information may be undetermined.
Evidence: Meaning of the information in relationship to a research question
Evidence is considered in context. What question are you trying to answer with the information?
- Direct evidence: Clearly states the answer to a research question
- Indirect evidence answers the question when combined with other evidence
- Negative evidence occurs in the absence of an expected situation.
Using the death certificate example, the death certificate is direct evidence for date of birth and date of death. Date of birth will be less reliable in most situations. An example of when the birthdate would be primary information and more reliable is when a mother is the informant for the death certificate of a child.
Indirect evidence requires organization and analysis! The timeline is one way to organize the evidence to see if it provides an answer to the overall goal of the research.
Negative evidence is the most challenging to understand and this blog entry by Diana Elder, Speaking Negatively: The Difference Between Negative Results and Negative Evidence, provides clarity. An example of negative results is looking for your family in the census and not finding them (which is recorded in your research log, of course!) An example of negative evidence is seeing a name occur year after year in a tax record, and then the name disappears. This supports the possibility that the person moved or died. This sentence from Diana’s blog sums up the relationship between the two nicely, “Perhaps the negative results of the searches will lead you to a conclusion using negative evidence.”
Analysis serves many purposes. The primary purpose evaluate the reliability of the information. Analysis supports the resolution of conflicting evidence since information from primary informants has greater weight than information provided by people who weren’t present at the time of the event. Analysis can also point you to an original document and reinforce the need to see it, if the original still exists. For complex genealogical research objectives, it will be necessary to consider all the various sources together and write an argument to support your conclusion, sometimes relying solely on indirect evidence.